In the past couple of years, there has been an increasing focus on diversity, equity, and inclusion (DEI) in evaluation. More and more practitioners are grounding their work in equity and providing guidance to other evaluators, including the Canadian Evaluation Society. Recognizing that equitable evaluation is an emerging area of work, this article aims to add to the growing discussion. While it does not include an exhaustive list of issues and strategies, it will help you introduce some changes to your evaluation practice.
Grounding an evaluation in DEI means the evaluation is equity-focused, culturally responsive, and participatory. In addition, such evaluation examines structural and systemic barriers that create and sustain oppression.
Inclusive and equitable evaluation requires continuous unlearning of old practices and learning of new ones. Questioning, practicing, and reflecting are also important in DEI. To bolster equity efforts, re-examine current practices and paradigms, since historically and presently, well-intentioned evaluation practices have at times dragged equity efforts, and in some cases, reinforced inequalities.
Adopting DEI in evaluation starts with the organization. The implementation of DEI in the workplace is an integral step towards implementing an inclusive and equitable evaluation. In fact, it is challenging to implement equitable evaluation without organizational adoption and buy-in, as it requires explicit leadership support and the right organizational setting. DEI is not a quick fix; rather it is a continuous commitment to achieve equitable results.
Adoption of DEI in an organization may include the following:
-
An explicit DEI strategy and performance measurement plans;
-
DEI systems embedded in the culture and practiced consistently;
-
Visible commitment and accountability from leadership in incorporating DEI in decision making;
-
DEI practiced in recruitment and career advancement; and
-
Continuously evaluating DEI efforts, collecting data on DEI indicators, and adopting changes.
Adoption of DEI in evaluation starts at the evaluation initiation.
1. Evaluation Planning
Context
Aim to understand the community and the system to successfully engage and partner with communities/program recipients. Learning about the social, cultural, historical, and political context is critical to implement values-based and culturally relevant evaluation that promotes equity and justice. In addition, identify whose voice has been silenced, whose voice is seen as the “truth” and aim to understand the power dynamics driving the current reality.
For example, to effectively evaluate a program focusing on public safety in Canada or USA, the evaluator needs to understand the current and historical violence and mistreatment of Black and Indigenous people by police and the legal system.
Similarly, to evaluate vaccine hesitancy and/or resistance in Black and Indigenous communities, it is imperative to understand the widespread racism in medical research and medical care. Many in Black and Indigenous communities distrust medical professionals and the government, as they historically faced structural and systemic challenges in accessing services or being excluded from supports.
Team selection
Select a strong evaluation team with a good mix of skills, experience, knowledge, and perspectives. If possible, aim to have representation from the community that is being evaluated, and balance diversity in the team by considering gender, ethnicity, content knowledge, methodology expertise, and expertise and knowledge of participatory research and equity focused evaluation.
Stakeholders
Include key stakeholders in the evaluation. Stakeholders make the important evaluation decisions, starting from identifying which evaluation questions get asked, to methodology all the way to reporting. Intentionally and carefully select stakeholders to include in evaluation committees and evaluation activities other than data collection.
Historically, individuals from marginalized communities have not had a chance to participate in evaluation beyond providing data. Involve community members as stakeholders, co-creators, and collaborators and provide appropriate compensation. In addition, determine the degree of stakeholder participation, and clearly identify stakeholder roles (e.g., participate, consult, or make decisions). In some cases, engage stakeholders separately if there are power dynamics that cannot be resolved.
Evaluation Questions
Evaluation questions are the backbone of an evaluation, as all efforts are focused on addressing these questions. As the driver of the evaluation, include evaluation questions relevant to all stakeholders, including and especially those coming from the community. It is a common practice to focus and prioritize evaluation questions from program funders or leaders; however, such practice does not examine the program recipients’ values, and systemic and structural causes of problems in the community. It is likely that evaluations that only focus on the funder’s questions perpetuate the cycle of inequity and fail to address the root causes of the problem that program is attempting to address. (See our article for more tips on writing evaluation questions.)
Evaluation design
In the past, quantitative data has been viewed as more rigorous and accurate, however both quantitative and qualitative data have value in DEI evaluation. A mixed methods approach is ideal for equitable evaluation as it combines the strengths of quantitative and qualitative data, i.e., precise estimates, statistical differences, and breakdown into sub-groups with detailed descriptions, lived experiences and complex narratives. Although mixed methods is preferred, be sure to select an evaluation design that is suitable for the program, and context.
2. Data collection and analysis
Culturally appropriate methodology
Design the data collection approach to respect and fit the communities’ traditions, norms, and standards – of course, best practices in evaluation still should be applied.
Minimize bias
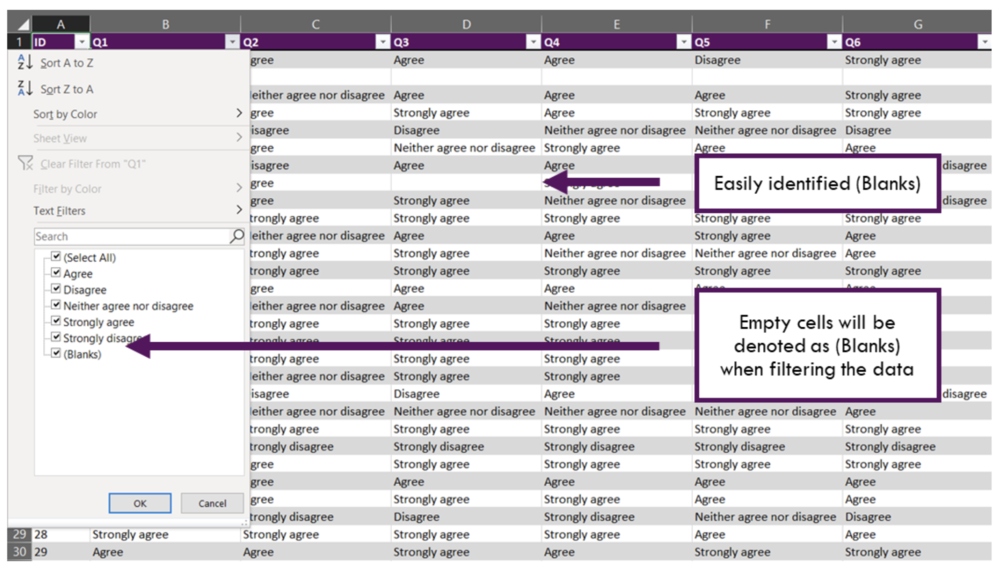
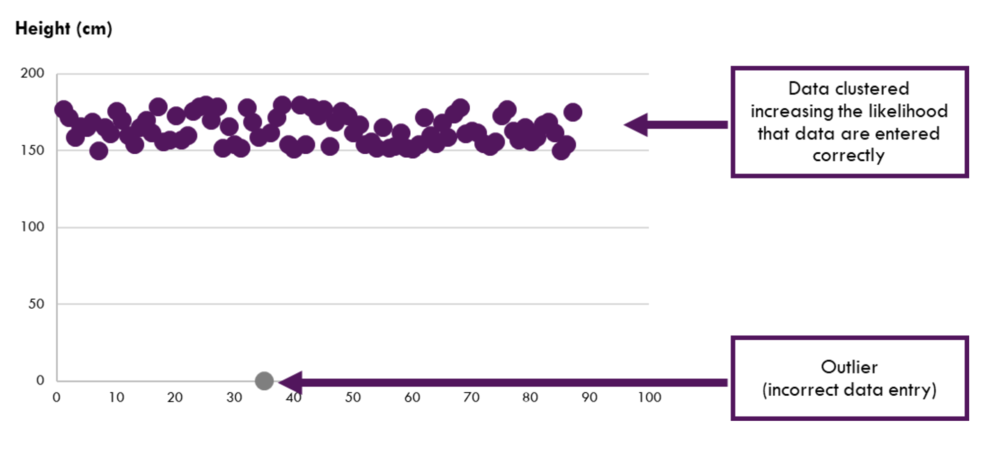
Bias is inevitable, however considerable efforts should be made to reduce all kinds of bias in data collection and analysis. Bias can occur in data collection and analysis, such as when surveys ask leading questions, or certain populations are over- or under- represented and the analysis failed to account for this situation. Make efforts to identify potential biases and strategies to address them, prior to and during the data collection and analysis stages.
Balance inclusivity and burden
Aim for adequate representation of marginalized communities in data collection, while considering the burden on the participants. Individuals from the community can provide valuable information; however, such benefits must be weighed against the harm done to individuals if the evaluation data collection efforts pose a significant burden.
Often, individuals from marginalized communities have served – and continue to serve – as a data source for evaluation and applied research purposes, with minimal benefit to the community. For example, the Downtown Eastside in Vancouver is home to the most marginalized and transient populations in Canada with high incidences of mental illness, substance use, communicable diseases, homelessness, and crime. The area has been a subject of extensive evaluation and research, serving as a data source for considerable literature published on peer-reviewed journals, reports, and dissertations. Although the evaluation findings from this area have influenced policies and practices locally and internationally (e.g., the use of safe consumption sites), the main problems and burden of disease observed in the area persist.
Identity-based data
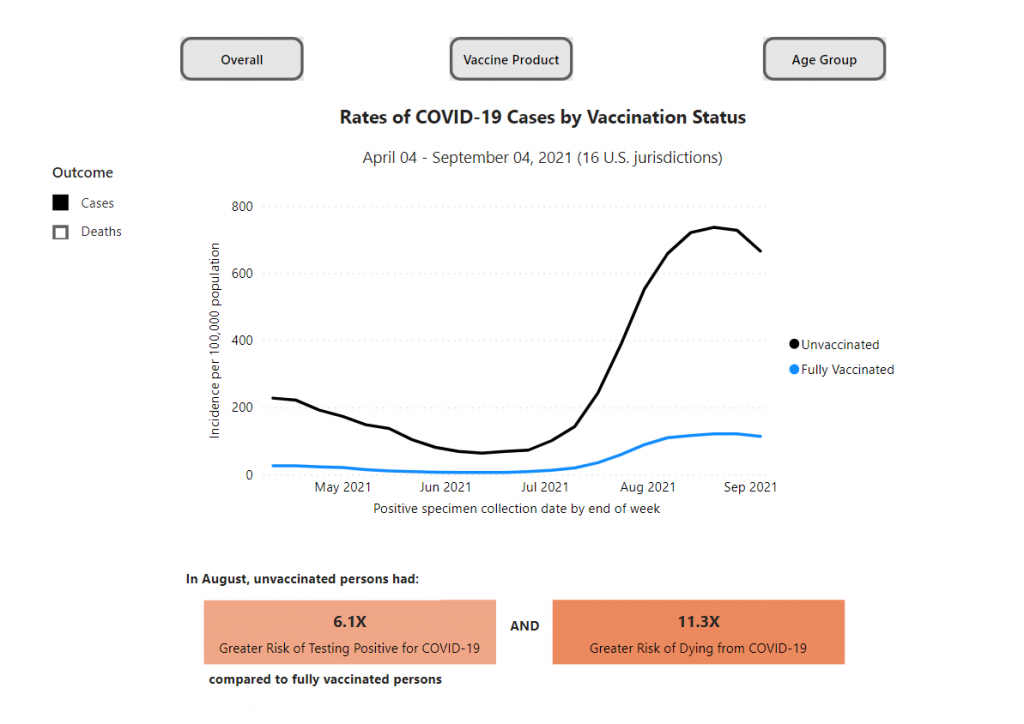
When collecting identity-based data such as ethnicity and gender, examine the utility, benefit, and relevance of the data to promote the well-being and rights of community members. Collecting identity-based data consistently from marginalized communities can demonstrate inequity in the system. For example, in the US, analyzing the burden of COVID-19 disease by ethnicity/race showed that Indigenous (2.4x), black (2.0x), and Hispanic/Latino (2.3x) communities were more likely to be infected, hospitalized and die from COV-19 as compared to white, non-Hispanic communities.
To promote equity and inclusion, use the data appropriately and safeguard it to ensure confidentiality and security. In addition,
-
ensure data quality to prevent further harm to marginalized communities;
-
collect data that examine and reflect structural disadvantages, root causes and/or discrimination; and
-
ensure that the evaluation team members involved in the collection, use, analysis and reporting of identity-based data are familiar with and adhere to privacy policy and legislation.
3. Reporting
Before reporting
Prior to formally documenting the evaluation results in a report, discuss the main evaluation findings with stakeholders. These early conversations show all stakeholders how their contributions were used and provide them with the chance to correct any inaccuracies and to clarify any misrepresentations. The selection of participants in this activity should refer to the stakeholder mapping identified at the planning stage, paying special attention to members of marginalised communities, who are often left out of discussions due to multiple kinds of constraints. Facilitate these discussions in an inclusive manner, by providing adequate time and space for reflection and meaningful participation.
Reporting
A good evaluation report will ensure the data is duly captured with balanced perspectives and fair representation of different points of view. The evaluation report is the most important evaluation deliverable, so methodology, limitations and findings need to be described in detail. When possible, the report should identify root causes and systemic and structural barriers.
In addition, ensure that the evaluation report
-
uses language and terms that are suitable for the community (e.g., the use of pronouns);
-
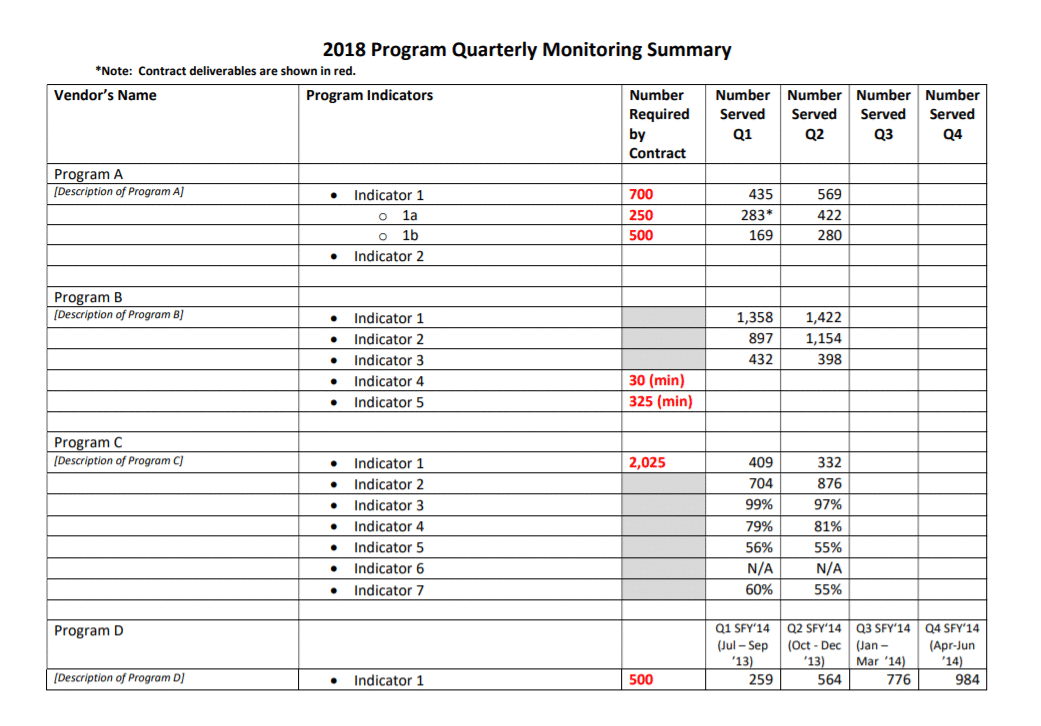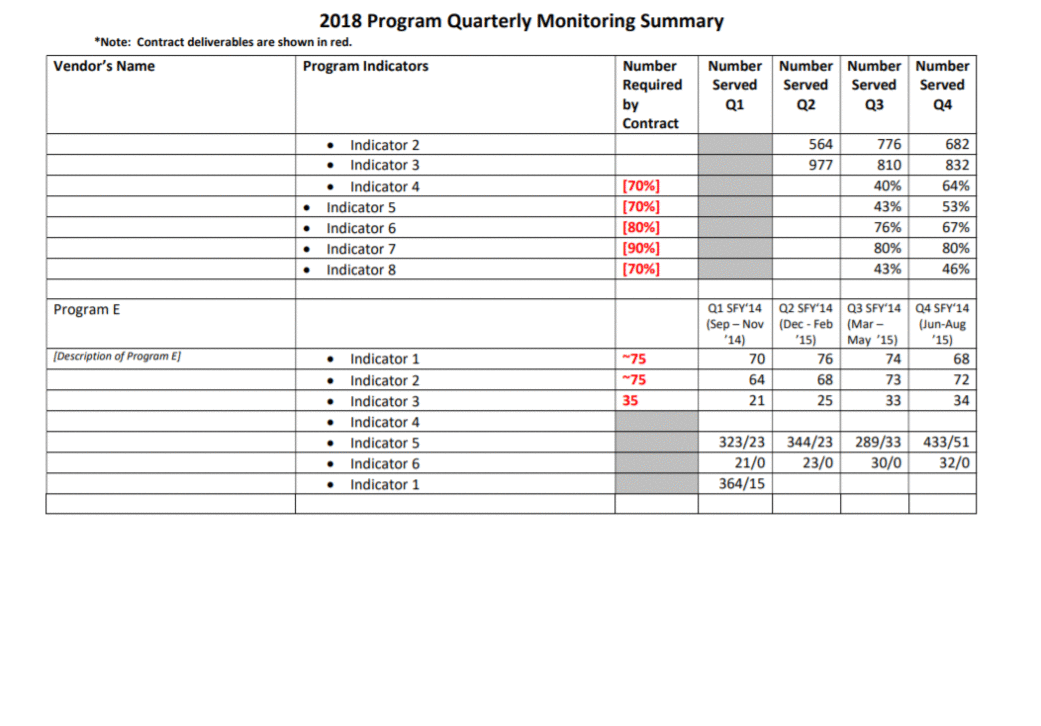
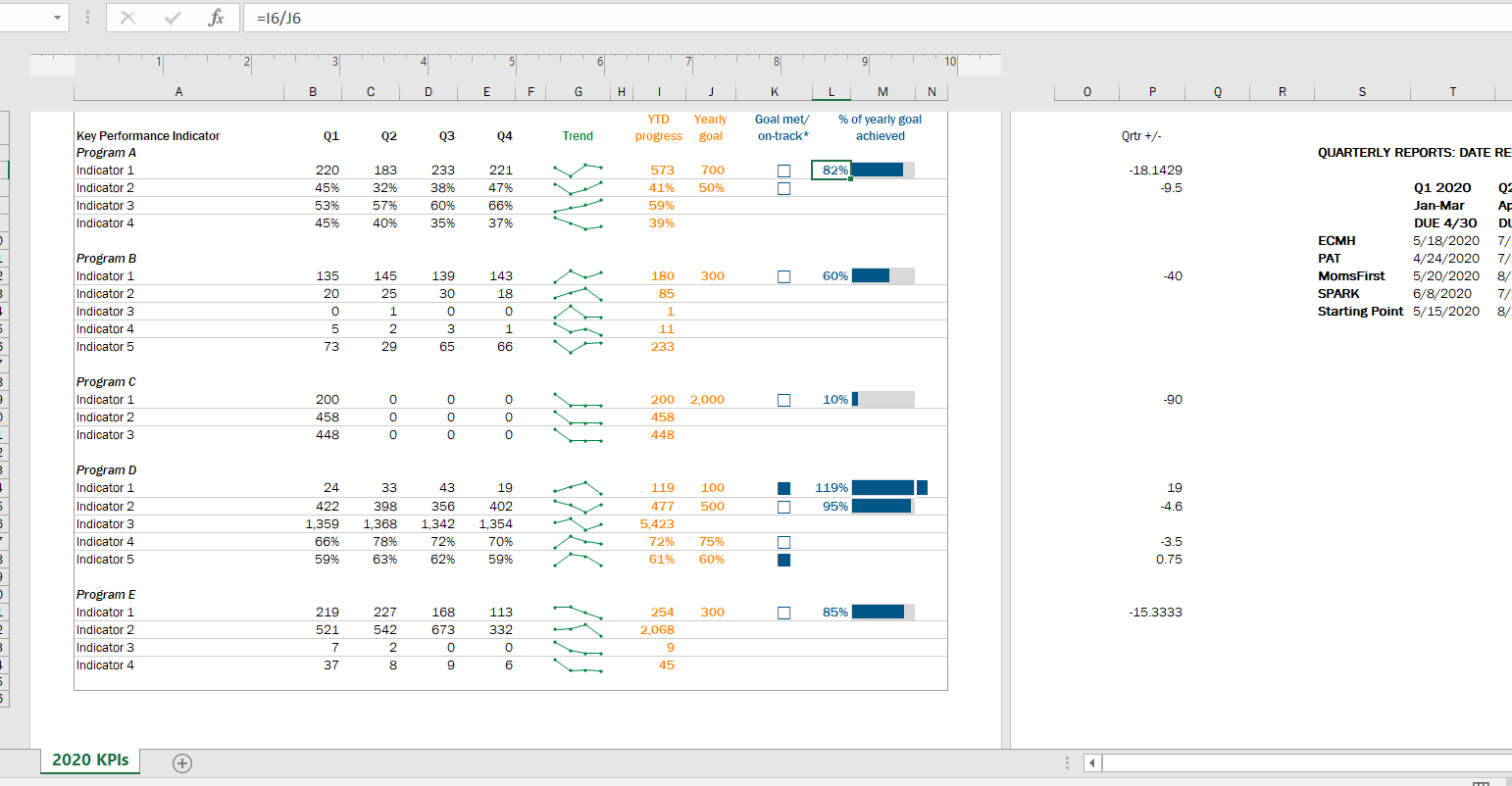
uses images intentionally and critically to ensure that images do not perpetuate stigma (e.g., using images of homeless people when working on substance abuse program evaluation); and
-
visualization is appropriate and culturally relevant (e.g., the use of red dots on a city map to show service recipients can make individuals feel like they are problem or burden for their community).
Overall, DEI in evaluation is a commitment to question our current standard of practice and continually reflect on our work to enhance programs, services, and systems for all, including marginalized and worst-off communities.
Check out our Program Evaluation Standards article and resource.
Sign up for our newsletter
We’ll let you know about our new content, and curate the best new evaluation resources from around the web!
We respect your privacy.
Thank you!
Sources:
-
Dean-Coffey, J., Casey, J., & Caldwell, L. D. (2014). Raising the Bar – Integrating Cultural Competence and Equity: Equitable Evaluation. The Foundation Review, 6(2). https://doi.org/10.9707/1944-5660.1203