This article is rated as:


Introduction
As evaluators, we are presented with a swath of data from varying sources, which often contains personally identifiable information (PII). PII includes any data which can be used to identify an individual. These data may include, but are not limited to:
-
Names
-
Date of birth
-
Addresses
-
Email addresses
-
Personal health numbers (PHNs)
Within Canada, there are data protection laws to safeguard PII, including the Personal Information Protection and Electronic Documents Act (PIPEDA) at the federal level and the Personal Information Protection Act (PIPA) in some provinces, such as Alberta. Each jurisdiction is likely to have its own major legislation, such as the U.S. Privacy Actand Health Insurance Portability and Accountability Act (HIPAA) in the United States or the General Data Protection Regulation (GDPR) in the European Union. While this article will not explore the details of these Acts, it is important to be aware of such legislation to ensure data are handled appropriately.
Under such legislation, PII is generally defined as: “personal information including any factual or subjective information, recorded or not, about an identifiable individual.”
In this article, we will outline some best practices for handling raw data to protect PII. For additional information, check out how to keep information confidential and anonymous.
Identify & Classify PII
Whether receiving data from within your organization (as an internal evaluator) or receiving data from a client’s organization (as an external evaluator), it is essential to review and identify all PII being collected. However, as PII can be any information that directly or indirectly identifies an individual, the process of identifying PII takes practice. For example, most demographic data could potentially reveal a person’s identity. However, while a full name directly identifies an individual, demographics like age or gender, when considered separately, may not be sufficient to identify an individual. It may require several demographic data combined to identify an individual. In such cases, it is necessary to categorize the PII in each data source to determine its relevance for the evaluation. If not essential, the PII should either not be collected in the first place or, if already collected, should be either removed or anonymized to maintain personal confidentiality.
During this identification and classification process, PII should be evaluated on:
-
The relevance of the PII being collected.
-
Are the PII required to adequately address the evaluation questions?
-
Note: Data being collected may serve other primary purposes, such as supporting registration, service delivery, etc. As evaluators, we do not delete or anonymize information from raw data sources being used to support operations but, rather, delete or anonymize information from our working data files to reduce the risk of unauthorized access to PII.
-
The sensitivity of the PII being collected.
-
Non-Sensitive PII: information easily gathered from public records, directories, or websites, including date of birth, gender, or postal code.
-
Sensitive PII: information that could potentially result in harm to the individual if data are breached, including personal health numbers (PHNs) or social insurance numbers (SINs).
-
Classifying data based on whether it is required for the evaluation, and on the sensitivity of said data, will inform your next steps. Required data containing PII may be worked with if appropriately managed and safeguarded (e.g., encrypting sensitive data). However, inessential data containing PII should be deleted (where appropriate) or anonymized to best protect the individual. With all PII, it is important to consider and abide by any information sharing agreements in place between your organization and the data owners (whether internal or external).
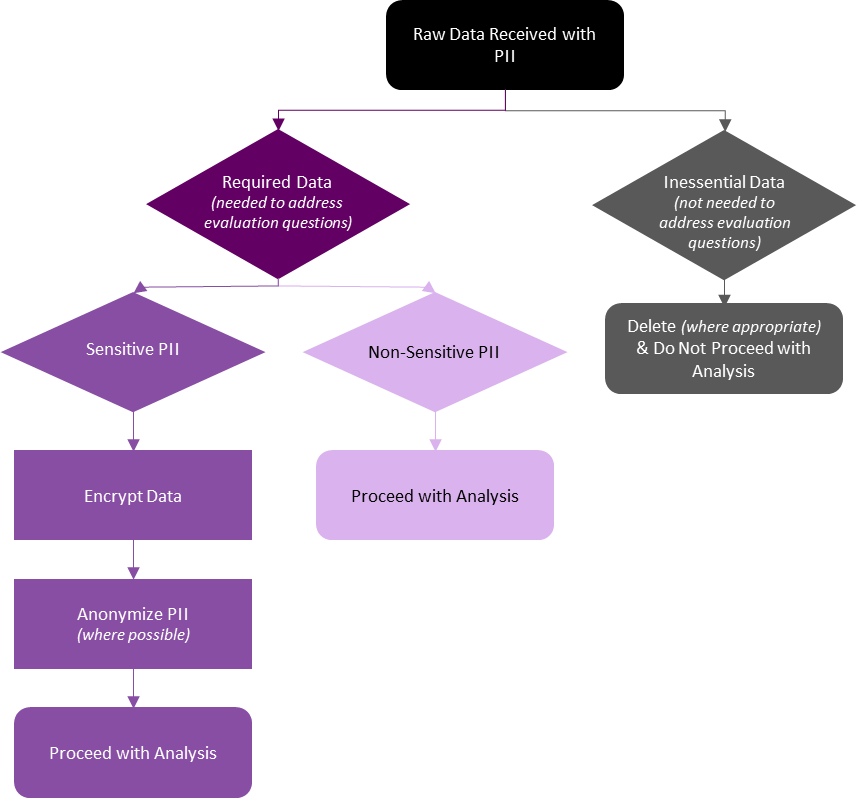
Inessential Data with PII
Data containing PII that are not required for your evaluation should be deleted or otherwise excluded from your analysis. However, methods for managing inessential data containing PII will be organization or context specific. Refer to your data privacy manual or connect with your data privacy officer as to next steps.
If inessential data with PII were collected, next steps may include:
-
Reporting to the client and/or data owner that PII were received.
-
Discussing with the client and/or data owner whether all data require deletion, or whether only the PII require deletion.
-
These conversations will determine whether you can personally remove the PII, or whether the data owner needs to remove the PII and resend the data.
-
-
Determining whether a full review of your information sharing agreement is required.
-
Do individuals need to be contacted about a breach in their personal information?
-
The key is to be aware of and eliminate inessential PII from raw and analysis files whenever possible. While these data may be harmless (e.g., inessential but non-sensitive), it is best practice to not store PII that will not be directly used in your evaluation.
Required Data with PII
If the PII are required for your evaluation, it is necessary to determine the sensitivity of said PII. Non-sensitive PII may not require any additional steps to safeguard the personal information, but sensitive PII will require additional safeguards (if not already in place).
Required and Sensitive PII
Required and sensitive PII need to be treated with additional care to protect the identities of the individuals captured in the raw data. These steps are best completed in the early stages of data collection but can be implemented in the data cleaning and analysis process if necessary. While these methods are not always necessary for non-sensitive data, they support data security for all PII and other sensitive data.
Encryption
Encrypting the raw data is essential to protect PII from unauthorized access. Encryption, “a security method for safeguarding data from unauthorized access”, is particularly important while data are in transit (e.g., when data are moving between devices via email), as data are more vulnerable while on the move. However, data at rest (e.g., when data are saved to your laptop’s drive) should also be encrypted.
-
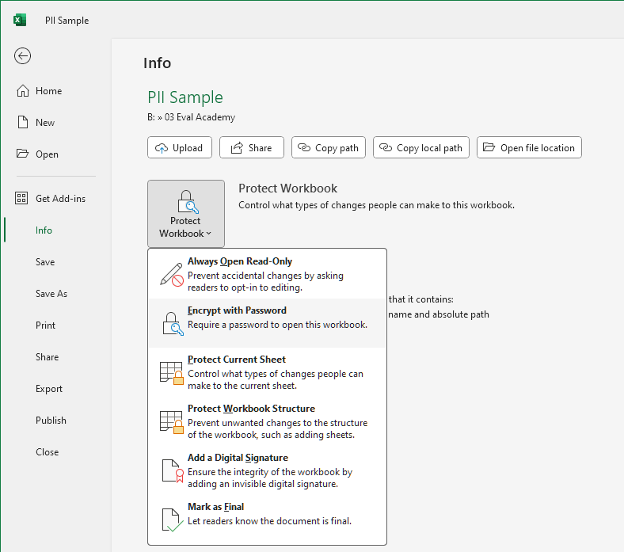
Go to the File tab in the top left corner of Excel
-
Under Info select Protect Workbook and Encrypt with Password
-
Enter and re-enter your password
-
The Excel spreadsheet will now be Encrypted
Note: Do not store your password with the encrypted file (e.g., saved to the same folder). Keep passwords private and separate from the data. If necessary, consider using an encrypted password management software.
Encrypt Multiple Files or Folders:
Usually encrypting the individual Excel file is sufficient. However, when storing larger amounts of PII or other sensitive data, you may consider using encryption software to safeguard your data. These can range from free open-source software (e.g., AESCrypt, VeraCrypt) to paid alternatives (e.g., AxCrypt, Folder Lock). If your organization uses a business communication platform like Microsoft Teams, your data are likely encrypted both in transit and at rest within the platform. However, you should thoroughly research any encryption software you may be using to ensure it meets your needs and adequately protects your sensitive data.
Anonymize PII
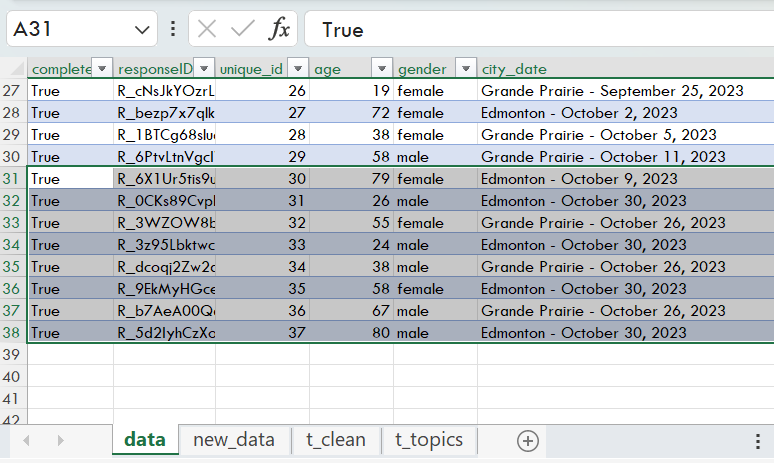
Anonymizing your PII is an additional method to protect your sensitive data. While there are numerous methods for anonymizing PII, a quick and efficient method is to use unique identifiers to replace some of the PII, such as names and personal health numbers (PHNs).
Creating Unique Identifiers:
-
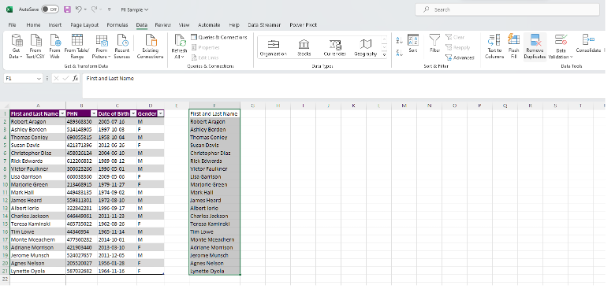
Identify which PII need to be anonymized. In this example, we will use First and Last Name.
-
Note: You may replace names with a unique identifier and still get accurate counts of unique individuals. However, you may still need unaltered date of birth or gender information for demographics analyses.
-
-
Get a unique list of First and Last Names by removing duplicates (if any)
-
Copy and paste (Ctrl + C, Ctrl + V) a duplicate list of the column you wish to anonymize
-
Highlight the new column and navigate to the Data tab
-
Select Remove Duplicates under the Data Tools section
-
-
Insert your anonymous code to the right of each unique First and Last Name
-
Use any random identifier that does not hint at the PII you are anonymizing
-
For ease, you can use sequential numbering with an ID prefix
-

-
Create a new column next to First and Last Name by right clicking on Column B and Insert. This will insert a blank new column next to First and Last Name.
-
Use the formula XLOOKUP to pull the unique identifier from your Unique ID table
-
=XLOOKUP([@[First and Last Name]],$G$2:$G$21,$H$2:$H$21)
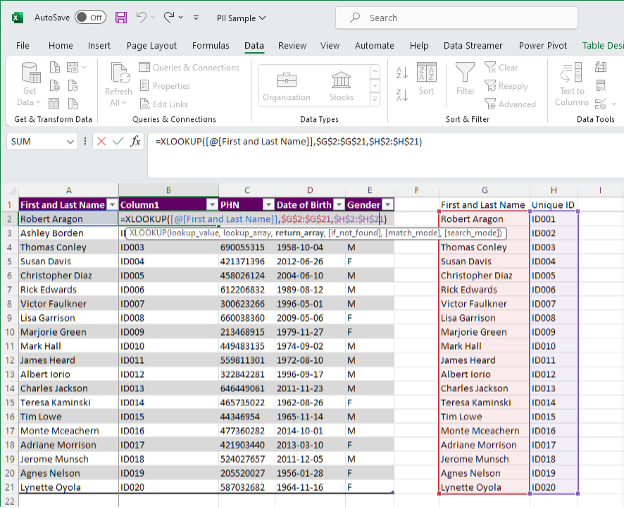
-
Replace the XLOOKUP formulae with raw Values
-
Highlight everything in Column B
-
Copy the column (Ctrl + C)
-
Right click in Cell B2 and Paste Special > Values (V)
-
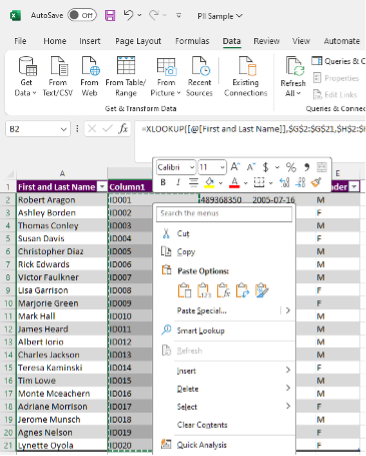
-
Remove the original First and Last Name column
-
Right click on Column A and Delete
-
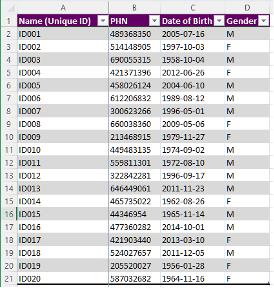
-
Next, copy and paste (Ctrl + C, Ctrl + V) the Unique ID table into a separate Excel document
-
Encrypt (see above) the new Excel file containing the Unique ID table
-
This encrypted Excel file will act as a key should you need to add more unique individuals to the data set
-
This will also provide you a method of re-identifying individuals, if required
-
Next Steps
Encrypting and anonymizing PII provide the backbone of protecting sensitive information that are required within your evaluations. These methods provide peace of mind that individuals’ data are safe against potential data breaches. Just remember to save passwords for encrypted files in a safe place separate from the data files or consider having a password convention within your team or organization to access these encrypted files.
However, data security does not stop with encryption and anonymization. For example, data should be retained for only as long as they are required and deleted when no longer required. Clear policies on data retention and deletion will ensure that you are not holding on to unnecessary data. Further, employees within your organization and/or within your clients’ organizations should be trained and aware of data privacy and security to help protect PII.
Wrapping Up
While we outline the initial steps to protect PII, it is important to continually monitor your data security measures. Following these best practices will set you and your organization on the right path in protecting PII and other sensitive information.